why attimis onebucket™ for snowflake
1. simplifying the delivery of new data sources
With traditional cloud object storage, every new data source requires:
- setting up a new endpoint
- configuring credentials
- validating connectivity
- managing region-specific behavior
- updating Snowflake with new volumes, stages, and paths
This becomes increasingly inefficient as the number of sources grows. Attimis OneBucket consolidates all data sources in a single unified namespace bucket. Once Snowflake is connected to Attimis, no new configuration is needed as additional sources are added behind the unified endpoint.
2. faster speed and improved query performance
When data is distributed across multiple storage environments, Snowflake must do additional work — authenticating multiple endpoints, connecting to multiple regions, joining data that lives in different places, and revalidating endpoints when inconsistencies occur.
Attimis removes these bottlenecks by presenting a unified namespace where all data appears under the same logical bucket. Snowflake reads from one endpoint and performs operations as if all data is stored in one place.
3. eliminating costly data migrations
Organizations often spend months migrating data to reduce cloud costs or consolidate workloads — expensive and disruptive. Attimis eliminates the need for these migrations: because all underlying sources sit behind a single endpoint, Snowflake can query data without relocating it. Attimis enables:
- opportunistic replication
- running analytics immediately, without physically moving any data
- reduced infrastructure and egress costs
- no transitions between cloud and on-prem environments
4. data governance, compliance, and security
Strict governance requirements dictate how and where data must be stored. Sensitive data must remain in approved locations — and under regulations like GDPR, traditional data migration can violate residency policies and create compliance issues.
Attimis provides a secure, unified data access layer that lets platforms like Snowflake query remote datasets in place, without physical migration. Because data remains in an approved, governed location, organizations maintain full compliance with residency requirements.
simplify and accelerate data into snowflake
While Snowflake can ingest data from many locations, each external source requires its own configuration, credentials, and validation — leading to complexity, slower onboarding, and fragmented access. Attimis OneBucket presents all storage locations through a single endpoint, so new sources become available in Snowflake without additional setup. Because the connection is always the same Attimis endpoint, Snowflake treats all new locations as already validated.
onebucket™: transparent to iceberg and parquet

integrating with external volumes and stages
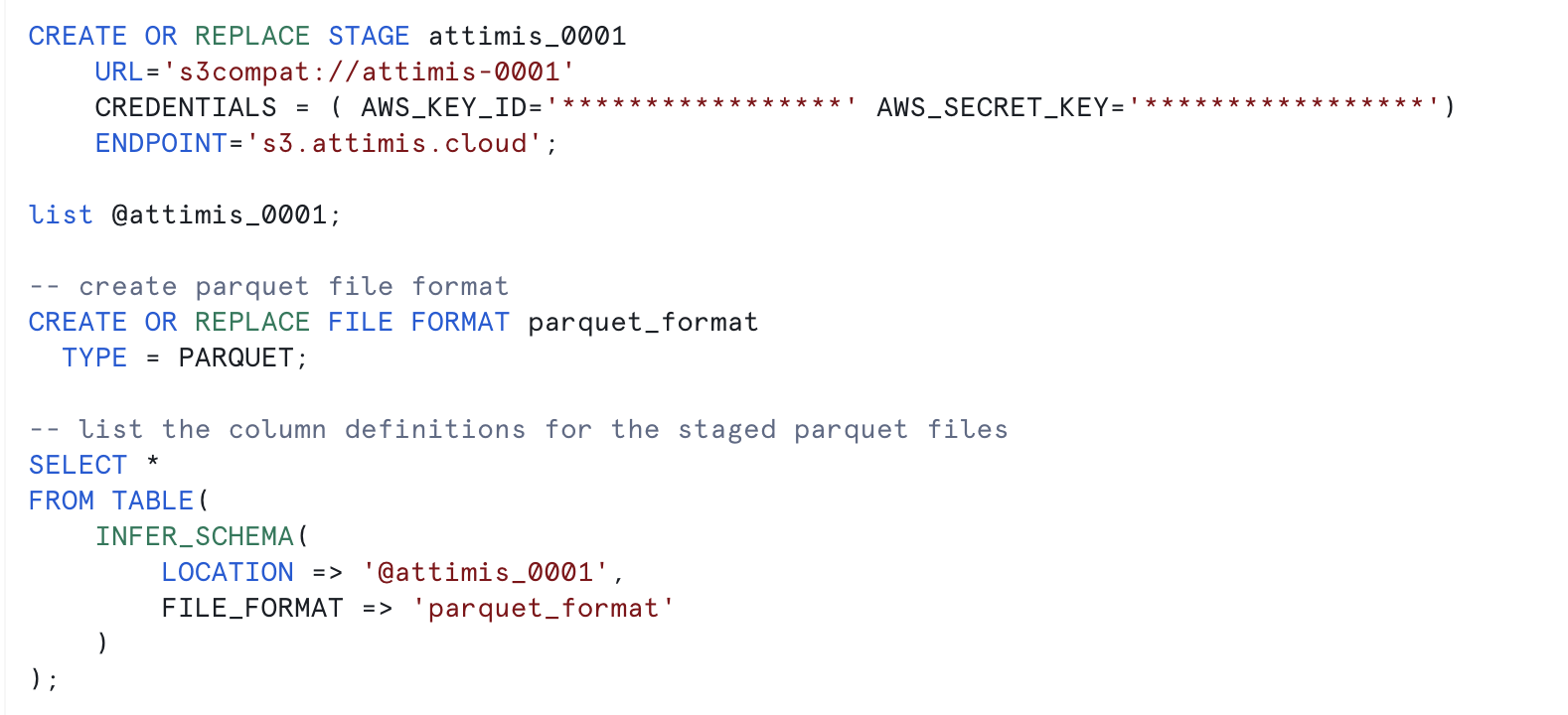
The integration begins by creating a Snowflake external volume that connects to the Attimis storage location, acting as a bridge. Because Attimis uses a unified namespace, Snowflake only needs to point to one endpoint.
Attimis S3-compatible parameters:
- one endpoint:
s3.attimis.cloud S3COMPATas the storage providerS3COMPAT://bucket-nameas the URL- standard credentials
AWS_KEY_ID = 'access-key'AWS_SECRET_KEY = 'secret-key'

Once the external volume exists, a Snowflake external stage can be defined using the same endpoint and credentials. Define a Parquet file format and use Snowflake's INFER_SCHEMA to align Iceberg tables with the structure of the Parquet files in the bucket.
creating and loading an iceberg table
With the external volume and stage defined, Snowflake can create an Iceberg table that uses the unified Attimis external volume as its storage location.

This creates a Snowflake-managed Iceberg table named attimis_iceberg. Populate it by loading data directly from the stage that points to the bucket location:
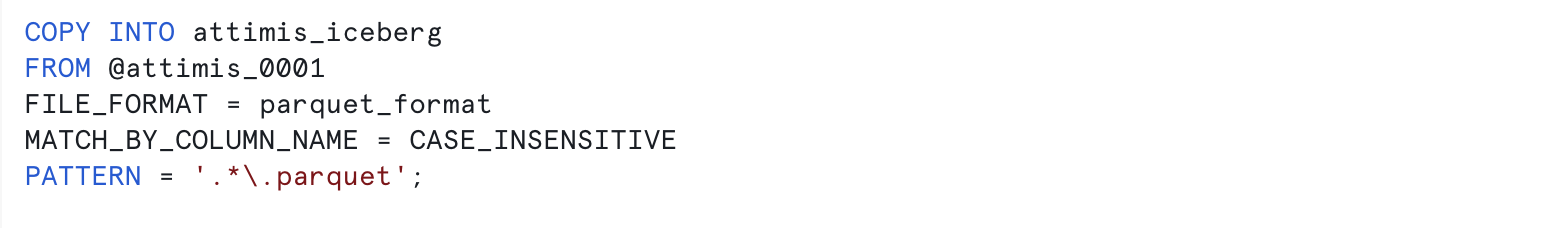
FILE_FORMATspecifies the format when reading the files (here,parquet_format).MATCH_BY_COLUMN_NAMEloads files by matching column names to the table.PATTERN = '.*\.parquet'ensures only Parquet files are loaded.
Once loaded, the Iceberg table is fully queryable through Snowflake, backed by Attimis's unified storage.
use case scenarios
scenario 1: migrating data from aws to on-prem
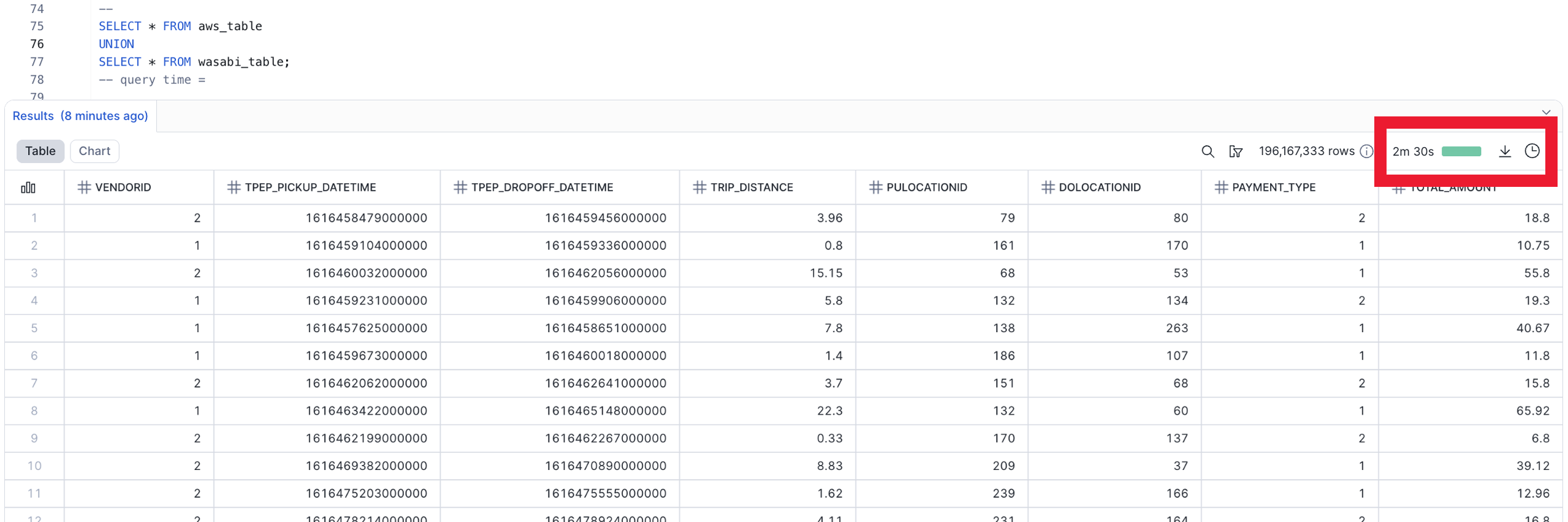
A customer wants to move data from AWS to on-prem to reduce costs. Traditionally this requires reconfiguring Snowflake endpoints, joining datasets across locations, and moving large amounts of data. With Attimis, both AWS and on-prem data appear in one unified bucket — no joins, no cross-location transfers.
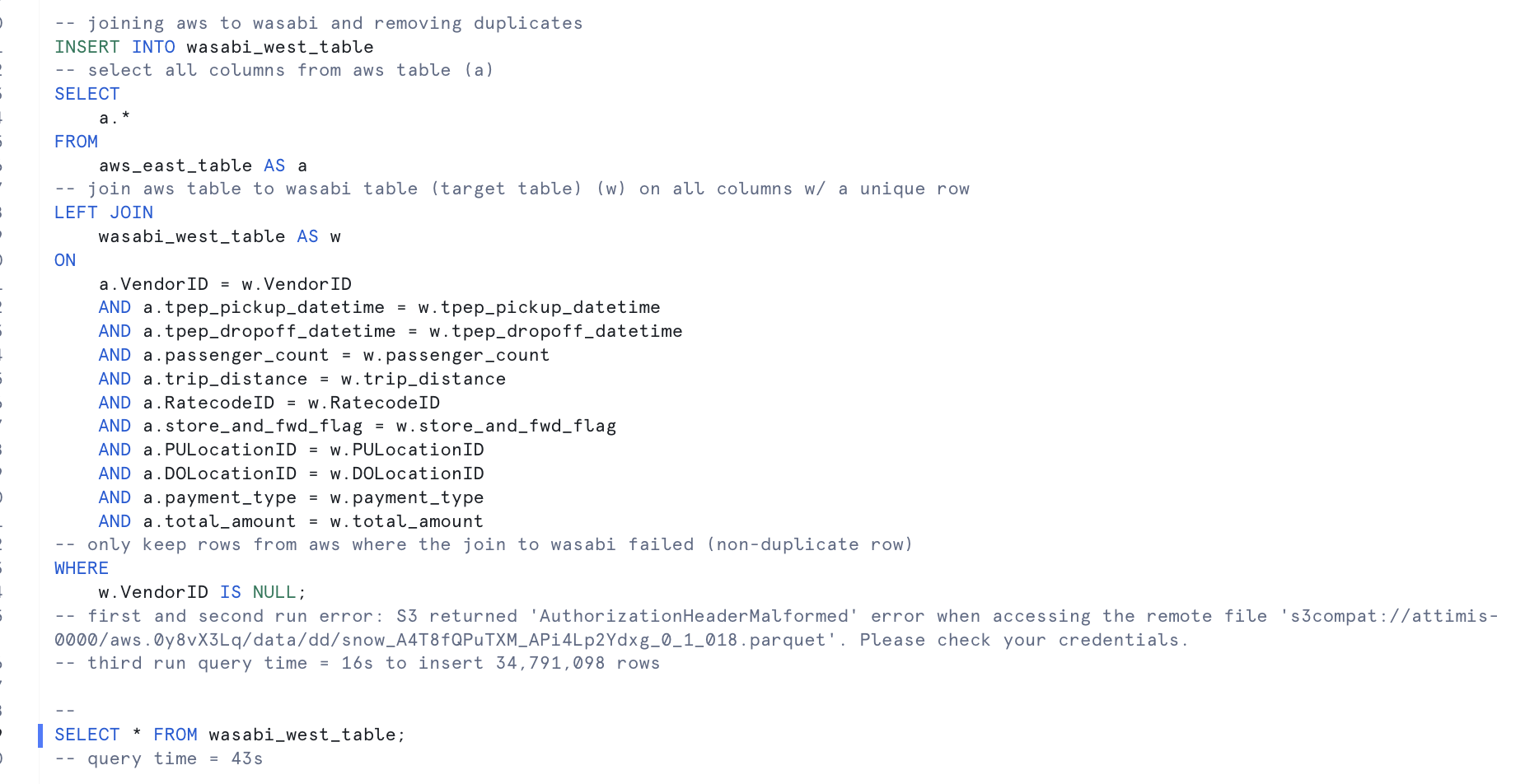
In testing, using AWS directly led to an intermittent AuthorizationHeaderMalformed error on the first attempt — a widely reported Snowflake-to-S3 issue resolved by simply rerunning the query. This does not occur with Attimis, which handles requests consistently without the intermittent mismatch, making it more dependable.
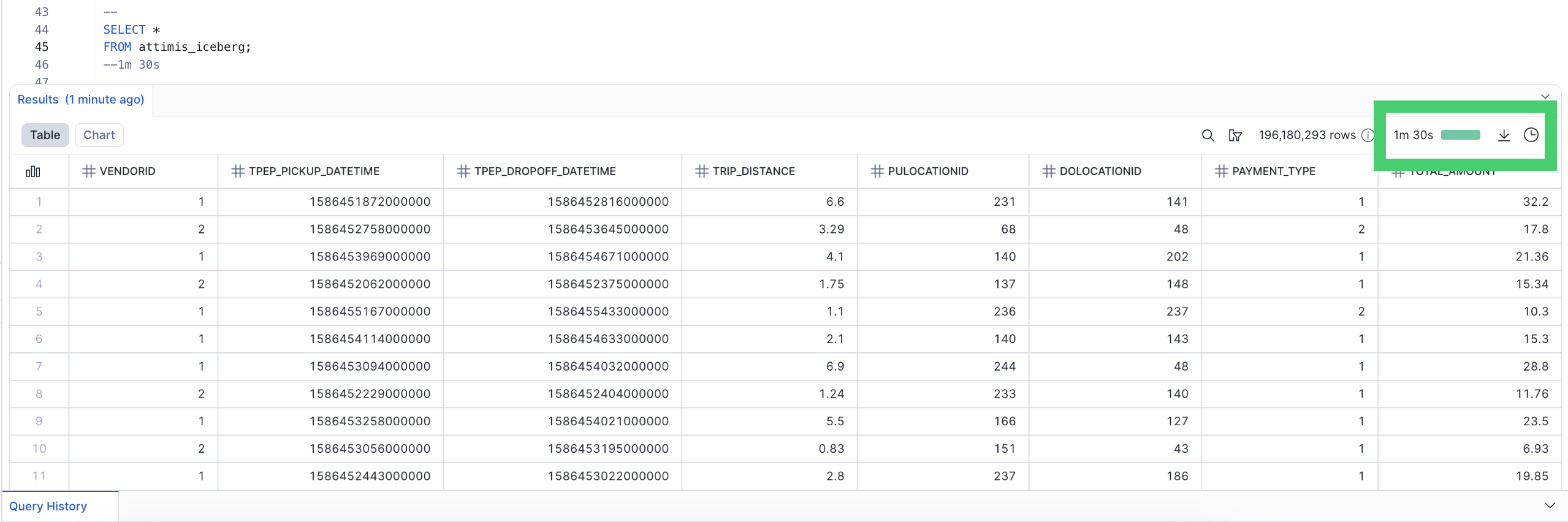
scenario 2: combining identical datasets across locations
Combining structurally identical datasets from different environments normally requires unions across Iceberg tables, adding complexity at enterprise scale. With Attimis, both datasets are already consolidated in a single unified namespace — Snowflake queries one bucket and a single combined table, eliminating multi-location unions.